
Du hast gerade den dritten "KI-Strategie"-Termin diesen Monat hinter dir. Viel Einordnung, viel Buzzword, wenig Handfestes. Und am Ende bleibt dieselbe Frage: Was genau passiert da gerade eigentlich, wie schnell geht das, und was bedeutet das für Entscheidungen, die heute schon Geld, Personal und Risiko binden?
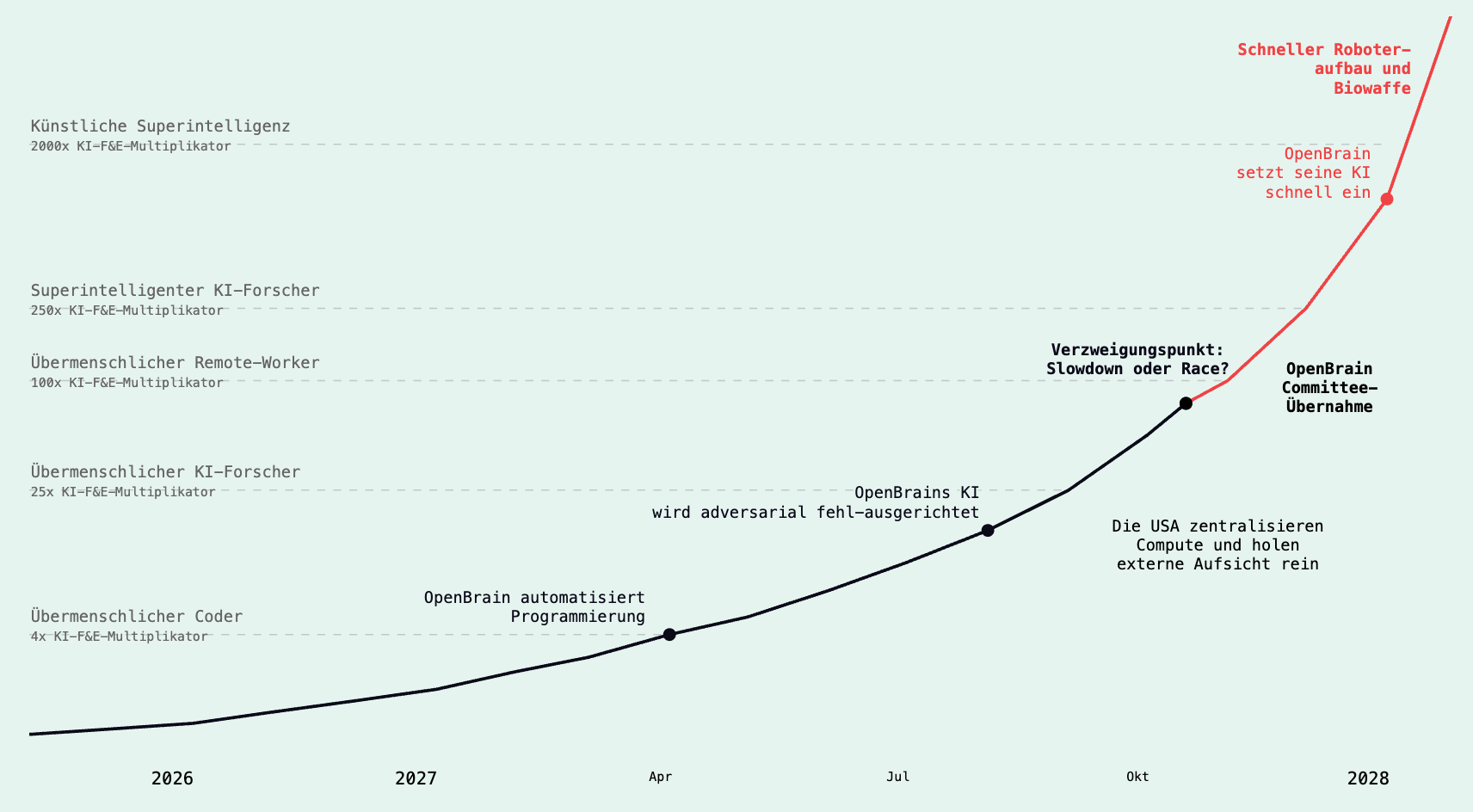
AI 2027 setzt genau an diesem Punkt an und erzählt seine Timeline seit Mitte 2025: Erste beeindruckende Ergebnisse mit Agenten, aber noch oft "stolpernd" im Alltag. Und es skizziert den Sprung zu heute Anfang 2026, wo gut spezifizierte Probleme plötzlich extrem schnell lösbar werden.
Hier ist unser ungewöhnliches, aber extrem konkretes Experiment: Wir haben ein reales Projekt als Messpunkt genommen.
KI-Omnibus ist unsere deutsche Adaption von AI 2027 (Szenario + Research-Seiten), einer forschungsgestützten KI-Szenarioprognose verschiedener internationaler KI-Spezialisten und independent Publisher (Daniel Kokotajlo, Scott Alexander, Thomas Larsen, Eli Lifland, Romeo Dean). Der eigentliche Punkt dieses Posts ist aber nicht nur der Inhalt, sondern die Build-Story, und was sie über den Stand der Technik verrät:
- Start: April 2025
- Fertigstellung/Hardening: Februar 2026
- Fakten: 144 dokumentierte Änderungsschritte (Commits) insgesamt, davon 90 am 11.02.2026 und 38 am 12.02.2026
These: Die Reibung zwischen Idee und umsetzbarer Realität verschwindet im digitalen Raum zunehmend. Und ein Teil davon ist: KI-Agenten können heute mehr von der Engineering-Arbeit wirklich tragen als noch 2025.
Was wir hier gebaut haben
KI-Omnibus ist eine Website, die das umfassende Paper AI 2027 für deutschsprachige Leser zugänglich macht:
- deutsche Adaption der Inhalte
- interaktive Darstellung wie im Original
- klare Quellen-/Footnote-Struktur und zusätzliche Research-Seiten
Warum wir es gebaut haben
Wenn du in einem KMU Entscheidungen triffst, hast du ein Problem: Das Thema ist zu wichtig, um es zu ignorieren, aber die Debatte ist oft zu vage, um daraus Handeln abzuleiten.
Uns ging es ähnlich, als wir versucht haben, unseren Eltern oder Freunden zu erklären, was von dieser Welle zu erwarten ist. Überall Schlagzeilen, Modellnamen und Infrastruktur-Ausbau, aber wenig ruhige, nicht sensationsgetrieben Einordnung.
Und wir sehen gerade einen Drift zwischen Consumer-KI und Pro-KI: Viele Endnutzer bleiben beim Chat (oft: ChatGPT). Der messbare Mehrwert entsteht aber dort, wo Agenten in echte Arbeitsumgebungen integriert sind, z. B. in Terminal/IDE (Claude Code) oder als agentische Coding-Tools (Codex), oder in komplett neuen Umgebungen, wie Cowork oder Manus.
KI-Omnibus ist genau aus dieser Motivation als Vibe-Sideproject entstanden, als AI 2027 im April 2025 auf ai-2027.com erschien: Wir wollten eine deutschsprachige, gut navigierbare Version plus Research-Seiten, die man ohne Twitter-Drama lesen kann - vor allem um es den Eltern oder der Oma zu zeigen.
AI 2027 war für uns interessant, weil es versucht Vagheit und Spekulation zu vermeiden. Und KI-Omnibus ist unser Versuch, dieses Material in den deutschsprachigen Raum zu bringen, ohne dass jede:r erst durch englische Longreads, PDFs, manuelle Übersetzungen, Berichterstattung und verstreute Links durchkämpfen muss.
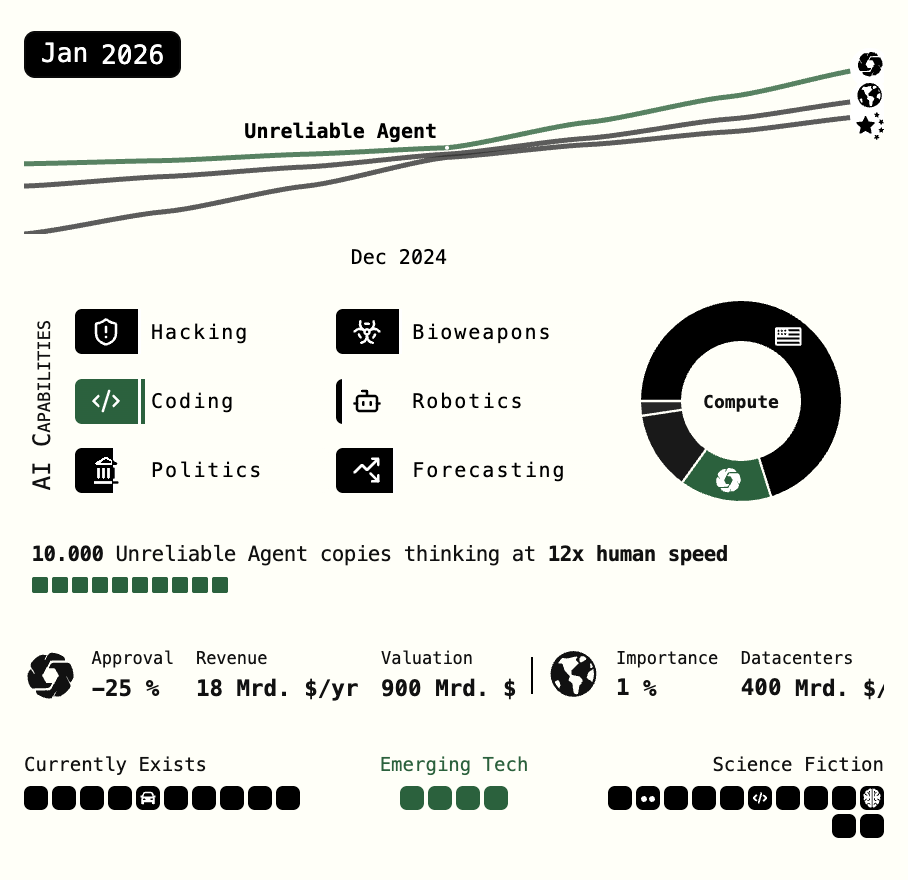
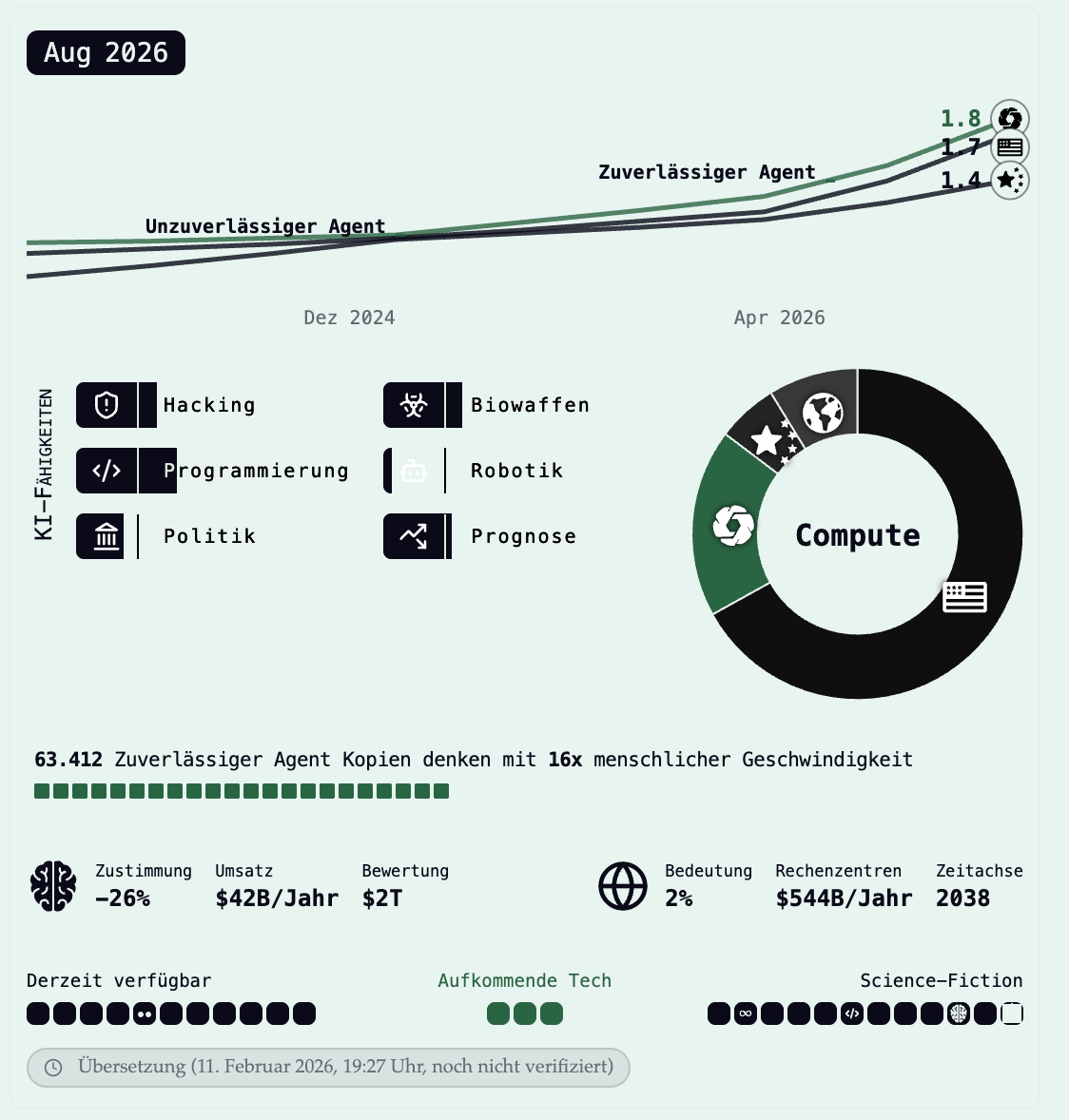
Original ai-2027.com dynamic Infographic links, reverse Engineered rechts.
Die Build-Story: April 2025 vs. Februar 2026
Der spannendste Teil am KI-Omnibus ist nicht nur was am Ende online ist, sondern wie das Ding überhaupt erstellt wurde. Wir arbeiten schon seit weit mehr als einem knappen Jahr täglich mit KI-Systemen. Dennoch sind wir auch selbst immer wieder baff, wie sich die Torpfosten verschieben.
Ein paar harte Fakten aus dem Projektverlauf:
- Start: 06. April 2025 (erste Umsetzungsphase)
- Ein richtig unangenehmer Teil: Nachbau (Reverse Engineering) einer interaktiven Infografik, obwohl wir keinen sauberen Einblick in die Original-Implementierung hatten
Dazwischen liegt die eigentliche Story:
- Frühphase (April 2025): Viel "Zähigkeitsarbeit" und hoher manueller Anteil. Damals waren Agenten (und die Workflows drumherum) deutlich weniger stabil. Man kommt zwar schnell relativ weit, aber man zahlt für die letzten Prozent mit vielen Human-in-the-Loop-Schleifen.
- Pause: Das Projekt lief nicht als Vollzeit-Initiative weiter, weil unser Fokus auf Firmenaufbau, produktiven Systemen und Kundenprojekten lag.
- Reaktivierung (Februar 2026): Wir haben es bewusst wieder hervorgeholt, um den Fortschritt der aktuellen Agenten-Generation zu testen (Codex 5.3, released am 5. Februar 2026) und in der Praxis an etwas handfesten aufzuzeigen. In Produktionen und intern arbeiten wir aktuell stark mit Claude-basierten Agenten, engineeren Ralph Loops, und Specifications. Das Adaptionsprojekt ist dagegen ein klassisches Vibe-Coding Projekt mit einer spannenden Voraussetzung: Man kann verhältnismäßig gut herausfinden ob das Ergebnis gut ist und funktioniert: Denn es gibt ja ein Original das man nachbaut. Das Ergebnis ist dennoch vergleichbar mit komplexeren Projekten: Der Takt wird kürzer, die Durchläufe wurden "sauberer", die autonome Arbeit deutlich stabiler, die Ergebnisse besser. Codex konnte in schnellster Zeit die Zusammenhänge aus dem alten Repository verstehen und die - damals mühevollen - Arbeiten mit ein wenig Guidance zu Ende führen.
Der Rest war letztendlich einfach:
- Fertigstellung/Hardening: Februar 2026
- Gesamt: 144 Änderungsschritte (Commits)
- Extremes Abschlussfenster: 90 Änderungen am 11. Februar 2026, 38 Änderungen am 12. Februar 2026
Was in diesem Abschlussfenster passiert ist, war nicht "nur Übersetzung", sondern klassisches Reverse-Engineering, sowie die eigentliche Delivery einer digitalen Veröffentlichung:
- Pick-up und Abschluss des Reverse-Engineerings der früheren Agenten
- Deploy-Pipeline und Release-Prozess
- SEO/Meta/OG/Sitemap/Icons
- Analytics und Security-Headers
- UX/Parität/Randfälle/Performance
AI 2027 erzählt seine Timeline nicht zufällig ab Mitte 2025. Im Text ist das die Phase der "stolpernden Agenten": beeindruckend in Demos, aber oft unzuverlässig im Alltag.
Ziemlich passend dazu startete unser KI-Omnibus-Projekt im April 2025. Wir konnten damals schon viel automatisieren und haben mit dem Vibe experimentiert, aber für die letzten Prozent (Parität, Debugging, Stabilität über ein riesiges und fragmentiertes Dokument) brauchte es deutlich mehr menschliche Führung und mehr Wiederanläufe. Letztendlich wäre es einfacher gewesen es einfach selbst zu machen - bis auf die Übersetzungen vielleicht.
Und genauso passend ist der Sprung zu Anfang 2026, wo AI 2027 das Motiv "Automatisierung der Programmierung" stark macht - das auch endgültig im öffentlichen Hype einschlägt: gut spezifizierte Probleme lassen sich extrem schnell lösen. Das ist auch die Brücke zu unserer eigenen Erfahrung im Februar 2026: Wenn Erwartung und Erfolgskriterium klar sind, wird die Umsetzung in vielen Teilen fast trivial. Der Teufel steckt - wie immer bei gutem Engineering - in einer ordentlichen Planung und der Bereitstellung der notwendigen Ressourcen. Agenten lösen Probleme jetzt nicht besser, weil es keine Komplexität mehr gibt, sondern weil Agenten immer besser darin werden, sich entlang einer Spezifikation bis zur validierbaren Ziel-Linie vorzuarbeiten.
Auf letzteres lohnt es sich genauer einzugehen, weil es eine ziemlich gute Messlatte für Agenten ist:
- Das Original ist nicht nur Text, bzw. ein komplexer wissenschaftlicher Artikel. Wir haben es mit einem visuellen System mit Interaktion (Scroll, Tooltips, Zustandslogik) und vielen Infografiken (teilweise Interaktiv) zu tun.
- Und selbst der Text ist nicht "ein durchgängiger Fließtext": Das Grunddokument hat mehrere Enden, dazu kommen viele Quellen, Sekundärinfos, Footnotes und Research-Seiten.
- Du musst zwischen mehreren Welten springen: gerenderte Seite verstehen, Datenquellen finden, Verhalten nachbauen, den aktuellen Stand überprüfbar machen und am Ende stabil ausliefern.
- Das Ergebnis ist nicht Geschmackssache: Es gibt eine klare Vorlage. Entweder die Infografik verhält sich korrekt oder sie bricht sichtbar. Interessant ist: Schon das Überprüfen ist nicht trivial, weil die Infografik sehr dynamisch ist (Scroll-getriebene Zustandswechsel, Timing, Layering).
- Als zusätzliche Komplikation geben wir vor das Frontend auf einem modernen React Stack mit Vite bereitzustellen. Zusätzlich wollen wir ja nicht einfach 1:1 kopieren, sondern müssen unsere Hinweise, sowie die Meta-Informationen zu T-0 und dem Übersetzungsprojekt unterbringen. Gerade dieses "Über uns", aber "nicht das 'Über uns' auf der Seite" war für die älteren Generationen der Modelle oft eine besondere Herausforderung.
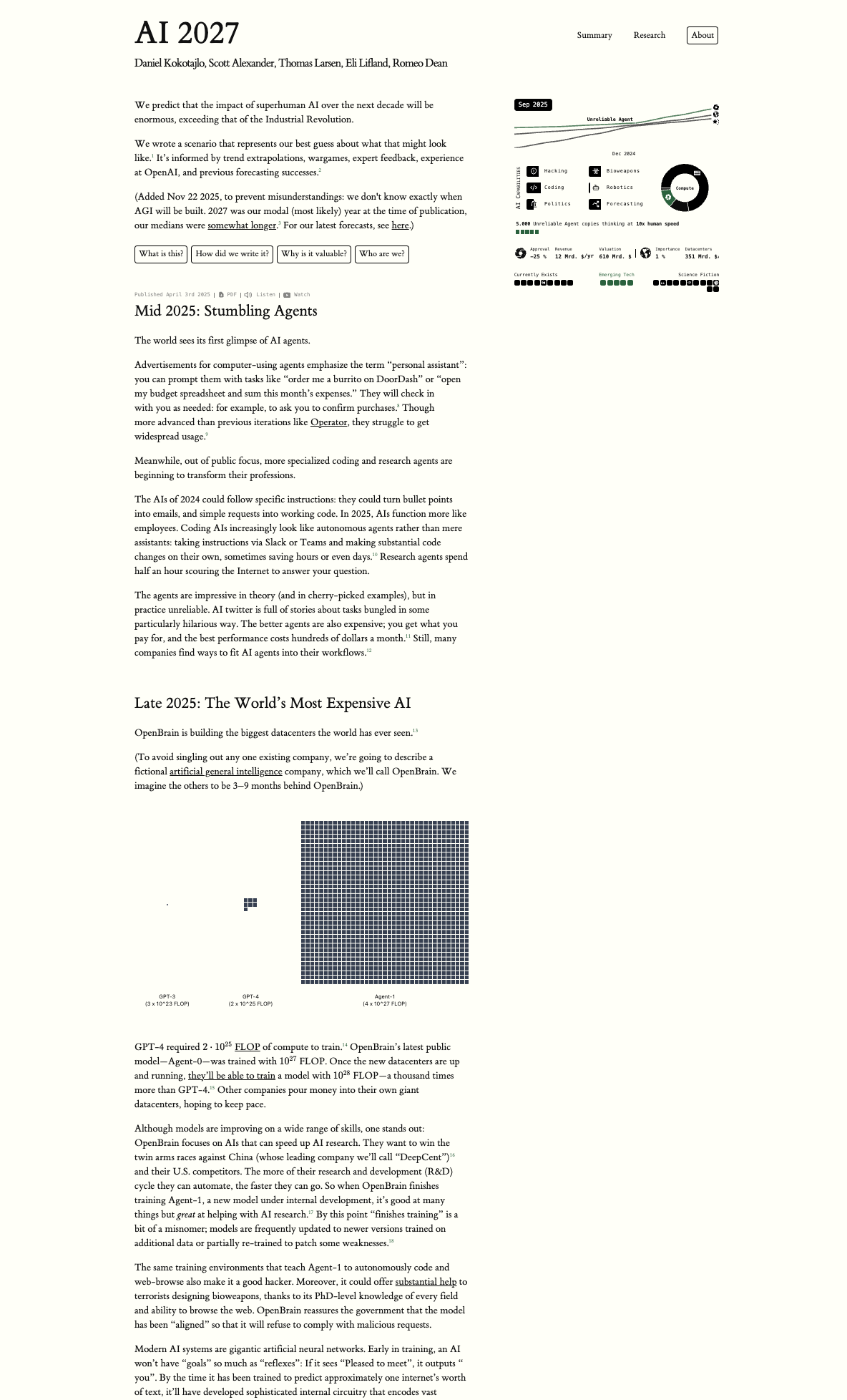

Wieder links Original, rechts adaptiert und übersetzt. Wir haben uns bewusst entschieden, das Design abzuändern und einen eigenen Rahmen zur Erklärung des Projekts hinzuzufügen. Der Rahmen wird negativ abgehoben um den ursprünglichen Umfang klar vom Originalinhalt abzugrenzen. Bei der Gestaltung wurden wir von Armadaquadrat unterstützt, die uns die neuesten React-Tricks gezeigt haben.
Warum das 2025 erstmal schwer war:
- Ein großer Teil des Verhaltens steckt nicht in "sauber scrape-barem" HTML, sondern in dynamischem Code und Zustandsübergängen.
- Die Datenlage war stellenweise indirekt (z. B. Daten in kompilierten Bundles statt in klaren JSONs).
- Browser-Automation und Scraping liefern schnell 80%, aber die letzten, grausamen 20% sind Debugging und vor allem Parität.
- Ja, man konnte die Originalseite schon damals per Screenshots/Beobachtung "sehen". Aber an der Kombination aus Umfang und Dynamik sind frühere Agenten häufig gestolpert: Übersetzungen mussten sektionsweise stabilisiert werden, Struktur und Aufteilung mussten viel härter vorgegeben werden, und große Dokumente fühlten sich schnell wie "zu groß für sauberes Arbeiten" an.
- Auch das Context-Engineering über mehrere Sessions war noch eine Herausforderung. Schon damals ließen sich zwar gewisse Prozesse über mehrere CLI Agents manuell parallelisieren (bspw. Retrieval in bestimmten Chunks). Standardisierten Context Protocols wie agents.md oder Skills steckten aber noch in den absoluten Kinderschuhen. Der erste Durchlauf im Februar wurde damals mit Agents in Cline und Gemini CLI (beide in VSCode) durchgeführt.
- Ein Agent, der in halbstündigen oder stündlichen Sessions autonom arbeitete (wenn auch oft in Fehler-Loops), war ein Erfolgserlebnis. Man hangelte sich durch. Mit unserer Coding-Erfahrung war es oft an Lächerlichkeit grenzend die Agents immer und immer wieder in Messer rennen zu sehen, die Intervention nötig machten.
Warum es Anfang 2026 deutlich leichter wurde:
- Bessere Models, bessere Agenten (bzw. Agent-Harnesses) + bessere Browser-Workflows (z. B. Playwright), Skills und Tools (bspw. via MCP-Protocol), reduzieren die Reibung pro HITL-Iteration drastisch (Parallelisierung, weniger manuelles Kontext-Schubsen)
- weniger "blindes Raten", mehr systematisches Durchtesten (was sehe ich, was sollte ich sehen, was ist anders?)
- Durch klare Guardrails und einen ordentlichen Scope wird aus einem Zähigkeitsproblem ein Engineering-Problem mit kurzer Taktung
- und: Suche statt Voll-Lesen. Agenten können heute viel besser in großen Dokument- und Codebeständen navigieren, gezielt Stellen finden und Änderungen iterativ verifizieren. Allein das macht bei einer Aufgabe dieser Größe einen dramatischen Effizienzgewinn.
Beispiel:
- Teile der dynamischen Infografik-Datenbasis wurden nicht "sauber extrahiert", sondern aus kompiliertem Quellcode gefunden (
panelData) und dann iterativ in eine stabile Scroll/State-Orchestrierung überführt.
Das ist genau die Art Arbeit, an der agentische Entwicklung in der Praxis entweder scheitert (endlose Debug-Loops) oder plötzlich kippt (schnelle Iteration mit weniger menschlicher Reibung).
Was das über den Stand der Technik bei KI-Agenten verrät
Wenn du Agenten nur als "Textgenerator" siehst, verpasst du schon lange den relevanten Teil. Der Unterschied für Unternehmen entsteht dort, wo Agenten nicht nur Content ausspucken, oder auf Context reagieren, sondern:
- in einem echten Arbeitsumfeld iterieren können (Code, Design, Content, Deploy, Tests - oder eine normale Arbeitsumgebung mit Werkzeugen wie E-Mail, Computer, Webbrowser, Software),
- Debugging tragen, Ergebnisse validieren,
- und technische Hardening-Arbeit beschleunigen (ohne dass du jede Kleinigkeit selbst zusammenklicken musst)
- auf ein Ziel hinarbeiten, bei dem gut messbar ist: erst aufhören, wenn das Resultat validierbar stimmt (keine schön klingenden Zwischenstände)
KI-Omnibus ist als Projekt ein brauchbarer Proxy, weil es kein Greenfield-Demo ist, sondern:
- viele zusammenhängende Baustellen hat (Content, UI, Build, Deploy, SEO, Security)
- echte "Integrationshärte" hat (Infografik/Parität/State): kein triviales Problem, weil es ein langes, verlinktes System ist (Quellen, Tooltips, Infosections, dynamische Bausteine). 2025 war das mit viel mehr menschlichen Eingriffen und Wiederanläufen verbunden.
- und am Ende in sehr kurzer Zeit von "fast fertig" zu "publish-ready" gehoben wurde: in zwei Tagen wurde ein Großteil der offenen Punkte nebenbei geschlossen. Mit der aktuellen Agenten-Generation (u. a. Codex 5.3 oder Opus 4.6) fühlte sich das im Vergleich zur frühen Phase fast wie ein anderes Spiel an.
Das ist kein Beweis, dass jetzt alles automatisch geht. Aber es ist ein belastbares Signal, dass sich die Wirtschaftlichkeit jeder Iteration verschoben hat.
Leitplanken (Rechte, Qualität, Grenzen)
- Attribution: KI-Omnibus ist nicht mit den Autor:innen von ai-2027.com verbunden. Das muss in der Gestaltung der Adaption klar erkennbar sein.
- Qualität: Übersetzung + Visualisierung sind Work in Progress und werden automatisch laufend nachgebessert (Siehe Übersetzungs-Timestamps per Abschnitt). Änderungen am Original wollen wir nachvollziehbar nachziehen (Changelog) und das Update-Monitoring weiter automatisieren. Wir freuen uns über Anregungen für bessere Übersetzungen.
- Zweck: Orientierung und Bildung über den SOTA von Künstlicher Intelligenz, keine Rechts-, Investitions- oder Sicherheitsberatung.
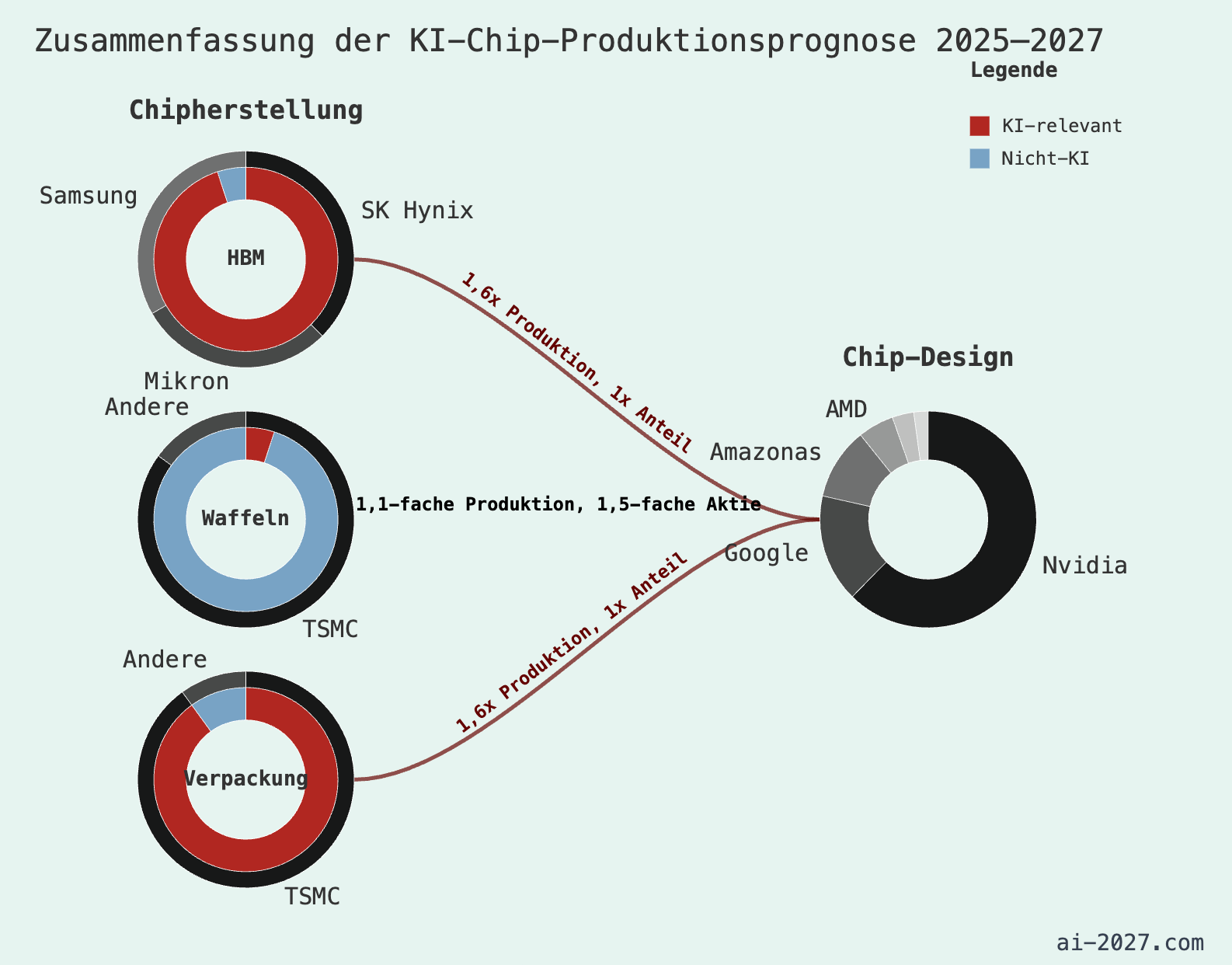
Was Entscheider daraus für die Praxis mitnehmen können
Wenn du nur eine Sache mitnimmst: Tempo ist jetzt ein strategischer Faktor und ein taktischer Vorteil. Nicht weil jede Firma morgen voll autonom sein muss, sondern weil Iterationskosten "Cost per completed Task" in vielen Bereichen rapide fallen werden. Teams jeder Größe können schon heute effektiver und effizienter mit KI Augmentation arbeiten und kommunizieren.
Klar: Man kann da nicht mitspielen wollen. Aber einige Wettbewerber werden sich bewegen. Und: Nicht alle werden wissen was sie da tun, aber die Torpfosten bewegen sich schneller als je zuvor.
Wir sehen drei wichtige pragmatische Implikationen:
- Mach Arbeit agent-ready, bevor du "Agenten" kaufst oder in Vendor Lock-in rennst. Wenn Prozesse, Rollen, Schnittstellen und Datenlage unklar sind, werden Agenten nicht magisch helfen, sondern Chaos beschleunigen.
- Bewerte KI-Projekte über Gesamtprozess, nicht über Demos und One-Shot-Services. Wer sich Vorteile verschaffen möchte achtet auf verlässlichen und nutzerfreundlichen Zugang zu KI-Systemen auf Organisationsebene, Hardening, Betrieb, Security, Monitoring und Verantwortlichkeiten. Und: der Stand der Technik verschiebt sich schnell. Gute Entscheidungen setzen deshalb auf robuste, bzw. antifragile Prinzipien und flexible Architektur statt auf eine einzelne Tool-Wette oder Vendor-Lock-in. Nie war die Gefahr bei IT-Entscheidungen größer, letztendlich auf das falsche Pferd zu setzen!
- Plane mit schnellerer Umsetzung, aber mit gleichbleibender Integrationshärte. Agenten reduzieren Reibung, aber sie ersetzen keine saubere Systemarchitektur, oder vernünftiges Onboarding. Nur weil man jetzt generell anders arbeiten kann, passiert es noch lange nicht von selbst und man muss dieses anders arbeiten auch erst einmal lernen.
Warum diese Lücke zwischen Können und Machen gerade im Mittelstand so groß ist, beschreiben wir in Der Agent Gap.
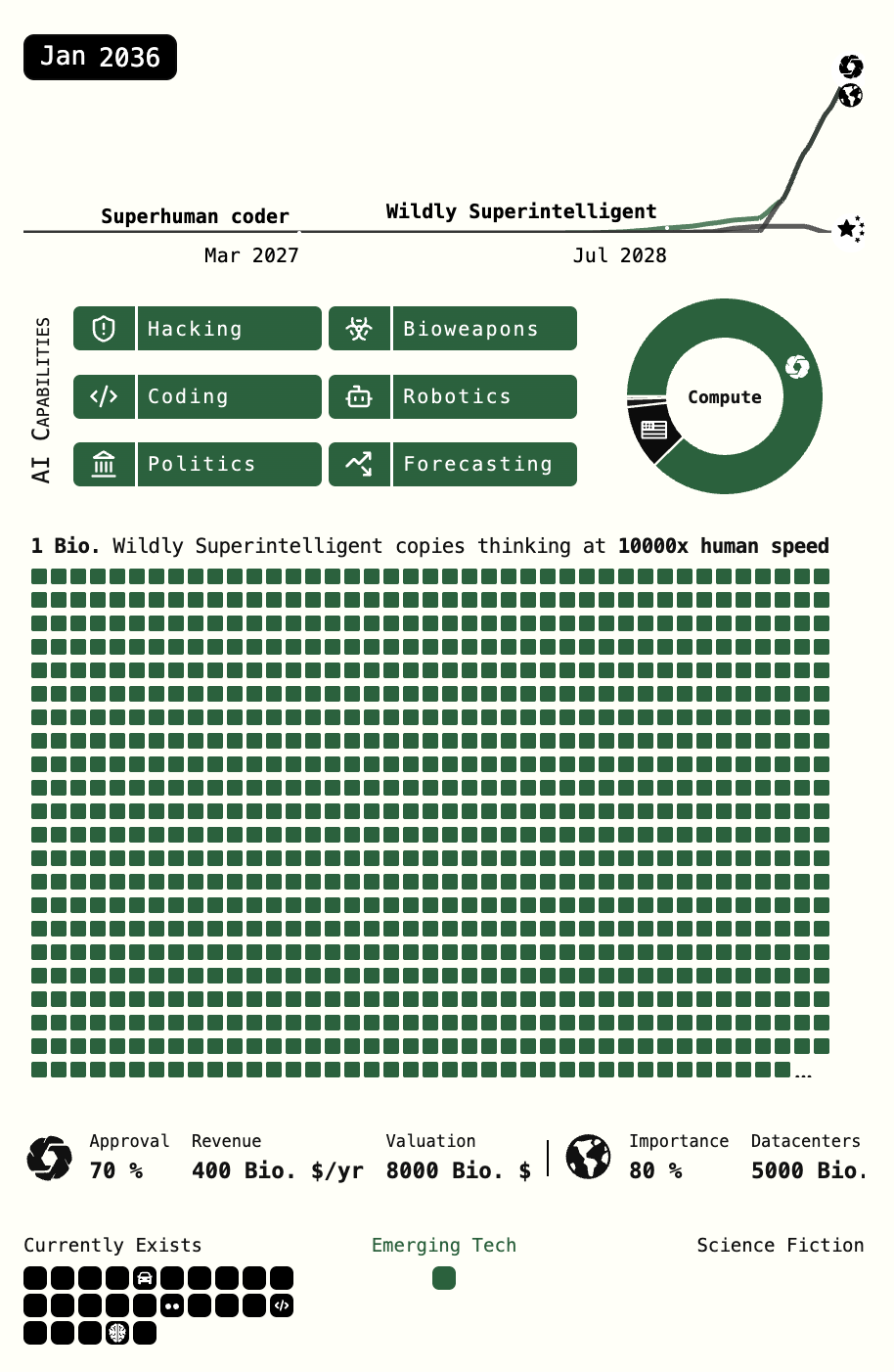
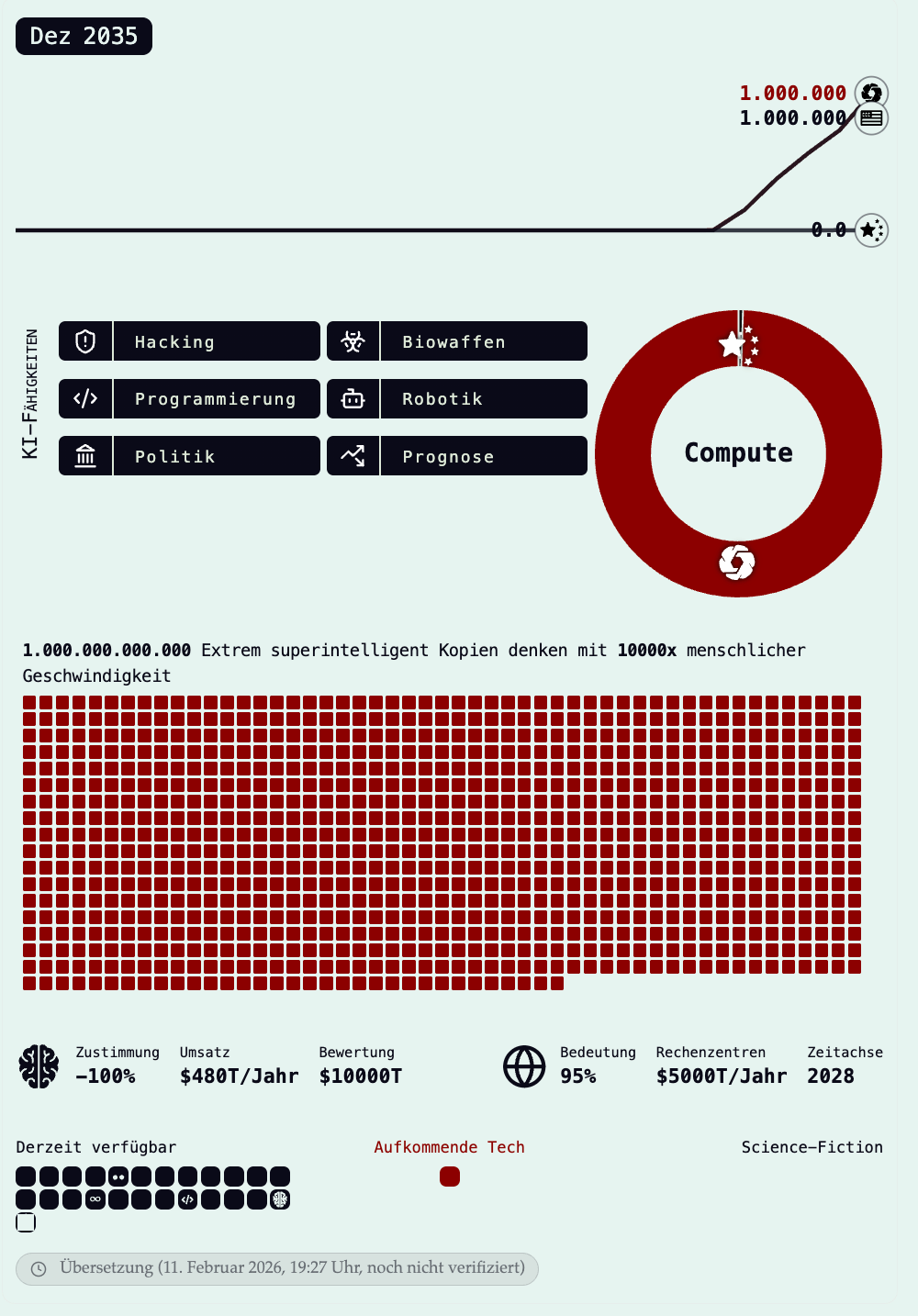
Ob uns KI in eine Utopie oder in den Abgrund führt ist unklar. Wahrscheinlich liegt die Wahrheit wie immer irgendwo dazwischen. Die Forscher zeigen auf, dass auf Grund der rapiden Beschleunigung der Entwicklung, Voraussagen über den Impact von KI schon über das Jahr 2027 sehr schwierig werden. In dieser kurzen Zeit werden zusätzlich gigantische Rechenkapazitäten geschaffen. Gleichzeitig nimmt die Regulierung international eher ab denn zu.
Was das im Alltag für Make/Buy-Entscheidungen bedeutet (Software, Design, "Digital Work"):
- Build wird günstiger, wenn die Spezifikation stimmt. Nicht "Prompt", sondern ein sauberer Arbeitsauftrag mit messbarer Abnahme (was gilt als fertig, was ist verboten, was sind Randfälle?).
- Buy bleibt oft sinnvoll für Plattformen, Build für Differenzierung. Kauf, wo du Standard willst (CMS, CRM, Datenbank, Ticketing). Bau, wo du Prozessvorteile willst (Glue, Workflows, interne Tools, Inhalte, Schnittstellen).
- Vendor-Auswahl verschiebt sich: APIs, Datenportabilität, Rechte, Auditierbarkeit und Change-Fähigkeit werden wichtiger als Feature-Listen.
- Key-Stakeholder positionieren sich als Builder in Unternehmen. Einzelne, befähigte Leistungsträger können mit KI-Augmentation die Arbeit ganzer Teams übernehmen und dabei durch weniger Fragmentation bessere Ergebnisse in weniger Zeit erarbeiten.
Warum sind das wertvolle Erkenntnisse? Weil das Muster weit über dieses Projekt hinausgeht. Reverse Engineering funktioniert nicht nur für Infografiken, sondern auch für viele SaaS-Realitäten oder Alltagsaufgaben: Oberflächen, Reports und Workflows beobachten, Anforderungen ableiten, dann iterativ nachbauen, interpretieren oder automatisieren. Und: Viele dieser nervigen Schritte lassen sich heute skillifizieren. Wiederkehrende Abläufe werden zu klaren Agenten-Skills mit Guardrails, Checks und nachvollziehbaren Outputs. Das entlastet Entscheider und Stakeholder von Routineaufgaben und schafft Ressourcen für die wirklich schwierigen Fragen: Priorisierung, Risiken, Architektur, Verantwortung und Umsetzung im Betrieb.
Interesse an einem wirklich intelligenten Setup?
Wenn du KI-Agenten im Unternehmen nicht als Tool, sondern als echte Unterstützung auf Organisationsebene einsetzen willst, brauchst du vor allem: klare Spezifikation, saubere Workflows, und eine Umgebung, in der Qualität überprüfbar ist.
Wir nutzen Erstgespräche typischerweise, um drei Dinge in 30-45 Minuten zu klären:
- Welche Prozesse heute schon agent-ready sind (und welche nicht)
- Welche Risiken (Rechte, Daten, Compliance, Betrieb) du zuerst lösen musst
- Ob du eher kaufen, bauen oder hybrid fahren solltest
Links und nächste Schritte
Der Kernpunkt ist derselbe, den AI 2027 zwischen Mitte 2025 und Anfang 2026 als Trend beschreibt: Wenn du ein Problem so formulierst, dass es testbar und abnehmbar ist, wird Umsetzung plötzlich nicht mehr der Engpass. Die Konzentration verschiebt sich auf Spezifikation, Rechte, Datenzugang, Resource-Management, Verantwortlichkeiten und Betrieb.
- AI 2027 (Original): https://ai-2027.com/
- KI-Omnibus (DE): https://ki-omnibus.de/

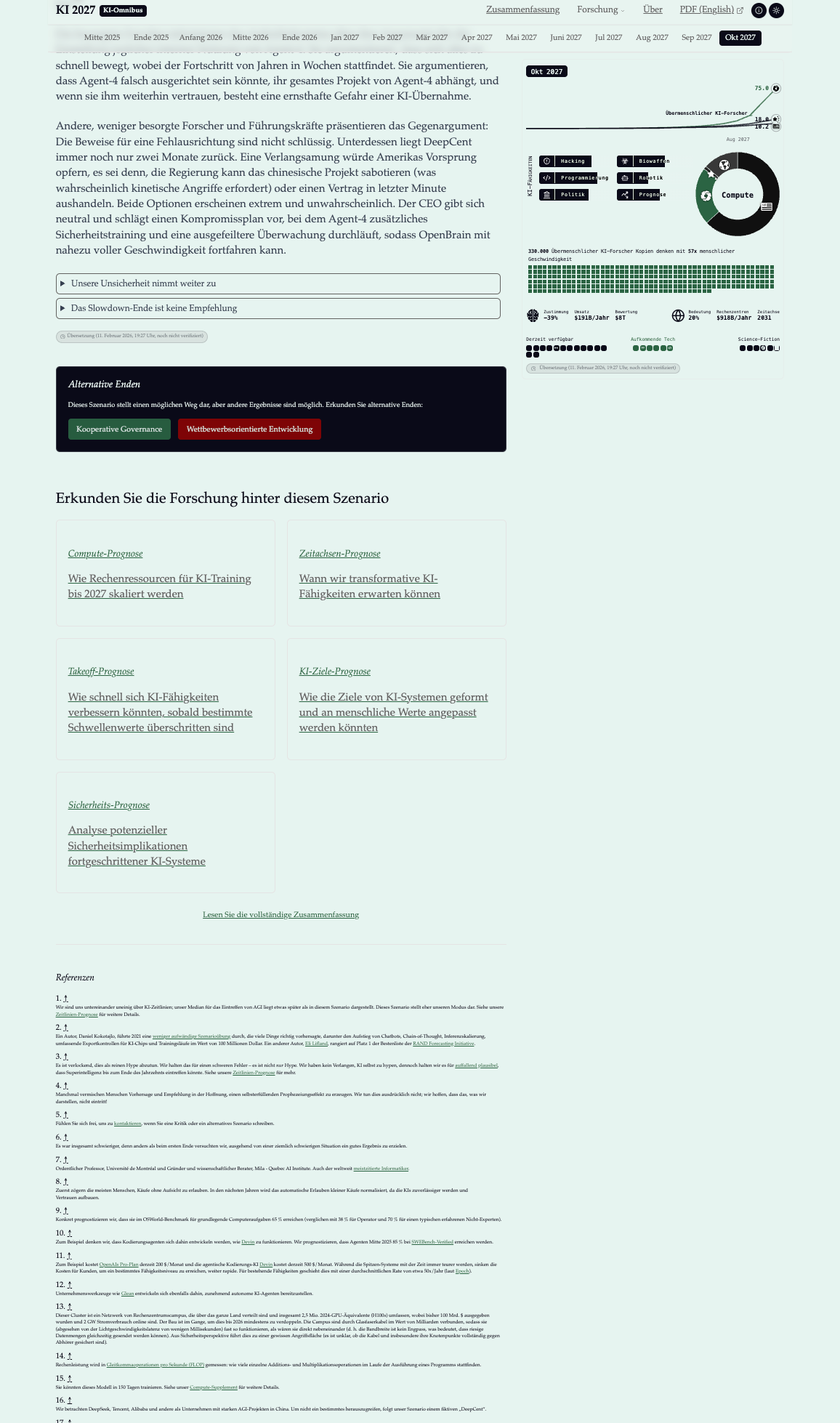
Wir haben die gesamten Inhalte inklusive der verschiedenen Szenarios und der Forschungs-Deepdives für deutsche Leser*innen übersetzt.
Ausblick: separater Post zur inhaltlichen Einordnung
Dieser Artikel war bewusst "Build-Story first". Im nächsten Post machen wir das Gegenstück: Was AI 2027 inhaltlich für Entscheider bedeutet, mit klarer Einordnung, wo wir Handlungsbedarf sehen und Beispielen wie digitalisierte Unternehmen bereits heute mit SOTA KI-Systemen arbeiten.
Referenzen - Veröffentlichungen zum AI 2027 Forschungsprojekt:
- DIE ZEIT (ZEITmagazin): „Daniel Kokotajlo: ‘Mir scheint, dass wir auf eine Katastrophe zusteuern’“ (zeit.de)
- Der Tagesspiegel: „Sie beschleunigt sich selbst: Wie künstliche Intelligenz unsere Welt verändert – lange bevor wir es merken“ (tagesspiegel.de)
- Handelsblatt: „KI-Briefing: Künstliche Intelligenz erzeugt schleichende Vertrauenskrise“ (handelsblatt.com)
- Golem.de: „AI 2027: In ein paar Jahren könnte es vorbei sein“ (golem.de)
- der Freitag: „Und niemand wird den Stecker ziehen“ (freitag.de)
- Sonntagsblatt: „AI 2027: Werden wir die Kontrolle über Künstliche Intelligenz verlieren?“ (sonntagsblatt.de)
- BR24 (Der KI-Podcast): „Was machen die Mächtigen mit KI?“ (br.de)
- Münchner Merkur: „Wann wird KI die Welt zerstören? …“ (merkur.de)
- all-ai.de: „Der 24-Monate-Plan zur Superintelligenz – Fakt oder Fiktion?“ (all-ai.de)
Für wen wir schreiben
- Entscheider in Unternehmen mit Ambition und Transformationswillen, aber ohne Lust auf IT-Großprojekte und endlose Prototypen.
- Teams, die einfache und komplexe Agents praktisch einsetzen und dabei die Governance behalten möchten.
- Shareholder, die einen genaueren Einblick in den Stand der Technik mit unabhängigen Analysen wünschen.
Wer hinter T‑0 steckt
- Ein interdisziplinäres Team aus Beratung, Psychologie, Software Engineering, Design, KI-Spezialist*innen und DevOps. Crew kennenlernen
- Wir arbeiten mit Organisationen eingebettet – von Strategie über Implementierung bis Enablement.