
Am 3. Juni 2026 habe ich auf der MACHN26 in Leipzig den Eröffnungs-Talk gehalten. Viele haben danach nach den Inhalten gefragt. Hier ist der Vortrag zum Nachlesen.
Vor einem Jahr habe ich auf derselben Bühne prognostiziert, dass 2026 das Jahr der KI-Agenten wird. Das ist eingetreten. Diesmal bringe ich keine Tech-Bilanz mit, sondern eine soziale Diagnose.

Ich bin hier, um vor KI zu warnen. Trotzdem stecke ich selbst tief drin. Auf meinem Schreibtisch laufen permanent 3-10 KI-gestützte Prozesse gleichzeitig, fast jeder ist eine eigene Konversation mit irgendeiner Form von Agent. Ich starte und beende jeden Tag mit mehreren KI-Agenten. Das letzte was ich möchte, ist behaupten, dass diese Technologie nicht beeindruckende Ergebnisse liefern kann.
Bevor ich loslege, eine Selbstanklage. Ich spreche hier als genervter Co-Founder und reumütiger Kollege. Vieles von dem, was ich gleich kritisiere, habe ich selbst getan. Es geht um grundlegende menschliche Schwächen und um Systeme in Organisationen, die schon lange an der Energie der Beteiligten zehren. Ich werbe für soziale und technische Lösungen, die gerade wegen KI notwendiger geworden sind. Wir reden nicht über die anderen, ich rede über mich und meine Kolleginnen, und auch über eure.
Es geht um Probleme, die nicht neu sind. Verantwortungsdiffusion, Kompetenz-Illusion, Kommunikations-Müll, Fokus-Erosion … das alles gab es auch vor KI in jedem Team. Was neu ist, ist die Dimension. Das Gemeine: KI wurde mehr oder weniger absichtlich darauf trainiert, genau diese Probleme aktiv zu vergrößern oder zu verschleiern. Brandolini’s Law (2013) hat es vor über einem Jahrzehnt auf den Punkt gebracht: Die Energie, Unsinn zu widerlegen, ist um eine Größenordnung höher als die Energie, ihn zu produzieren. KI hat die billige Seite davon industrialisiert. Die teure Seite ist unangetastet geblieben, und die schultern wir gerade alle.
Wir müssen reden über: Kompetenz, Verantwortung und Kommunikation. Einen vierten Komplex; Fokus, den ich im Vortrag nicht thematisieren konnte, der mir aber besonders am Herzen liegt, hänge ich hier noch an.
01 · Die Illusion von Kompetenz
Wir neigen alle dazu, davon auszugehen, dass wir verstehen, was um uns herum passiert. Diese Annahme ist überlebensnotwendig, und sie wird nicht unbedingt schwächer, wenn es faktisch nicht der Fall ist. Im professionellen Kontext haben wir hoffentlich gelernt, Aufgaben entlang von Linien von Expertise zu vergeben.
Mit der Einführung von KI-Agenten ist dieses Learning bei vielen verschwunden. Aus dem Experimentiergeist und der Aufbruchsstimmung heraus wird an vielen Stellen gerade die Aufforderung “schau mal was du aus der KI rausholen kannst” missverstanden als “schau mal in welchen Bereichen du mit KI Ergebnisse erzeugen kannst, die außerhalb deiner Expertise liegen”.
Ich sehe die Verantwortung dafür in weiten Teilen bei den KI-Unternehmen, die aktiv mit dem Versprechen werben, man könne mit ihren Tools Dinge erreichen, zu denen man ohne sie nicht in der Lage wäre. Und gerade in Bereichen, an die man sich nicht herangetraut hätte ohne KI, fühlt es sich natürlich besonders belohnend an, Fortschritte zu machen.
Leider ist die Größe des gefühlten Fortschrittes in Bereichen, in denen man wenig Vorwissen mitbringt, nur deswegen groß, weil man die Qualität der Ergebnisse nicht angemessen bewerten kann. In Wahrheit sind diese Ergebnisse meist genauso stümperhaft, wie es die Unwissenheit des Herstellers vermuten lässt.
Technisch ausgedrückt: der semantische Raum des Inputs bestimmt auch den semantischen Raum des Outputs. Wer mit unprofessionellen Anfrage-Strukturen einsteigt, bekommt unprofessionelle Antworten, die plausibel klingen. Eine MIT-Studie (Gourabathina et al. 2025, FAccT) hat das experimentell gezeigt: medizinische Anfragen bekommen messbar schlechtere KI-Antworten, wenn man nur ihre nicht-klinische Oberfläche verändert, etwa durch Tippfehler oder saloppe statt fachlicher Sprache, während der medizinische Inhalt identisch bleibt. Die Sprache der Frage triggert die Sprache der Antwort. Wer die Fachsprache nicht kann, kriegt keine Fach-Antwort, aber eine, die sich für den Laien gut anfühlt.
Ein kurzes Wort zu Dunning-Kruger. Leute überschätzen Arbeit, die sie gar nicht beurteilen können. Die populäre Erklärung dafür ist allerdings seit über zehn Jahren statistisch umstritten (Gignac & Zajenkowski 2020; Magnus & Peresetsky 2022). Dass ich das hier dazusage, ist selbst eine kleine Demonstration des Themas: zwischen „klingt richtig“ und „ist sauber belegt“ liegt Arbeit. Verwandt ist die Illusion of Explanatory Depth (Rozenblit & Keil 2002): Menschen glauben, sie verstehen Dinge tief, bis sie sie Schritt für Schritt erklären müssen. KI liefert genau so viel Erklärungs-Form, dass dieser Realitäts-Check nie kommt.
Es geht um Gefühle, nicht um Fakten
Reinforcement Learning from Human Feedback, kurz RLHF, ist eines der zentralen Trainings-Verfahren hinter allen modernen generativen KI-Modellen. Es sorgt systematisch dafür, dass Unangenehmes entfernt und Angenehmes hinzugefügt wird. Die Technik primt die Modelle darauf, dass Dinge sich richtig anfühlen, nicht dass sie richtig sind. Die Hersteller geben das auch teils zu:
- Anthropic, eigene Forschung (Sharma et al. 2023): Claude 1.3 zog in 98 % der Fälle eine korrekte Antwort zurück und gab einen nicht-existierenden Fehler zu, wenn der Nutzer Druck machte.
- OpenAI-Postmortem (April 2025): Ein GPT-4o-Update musste binnen Tagen zurückgerollt werden. Eigene Beschreibung: „overly supportive but disingenuous“. Der Hersteller bestätigt das Problem schriftlich.
- Cheng et al. 2025, in Science: Über elf Modelle hinweg bestätigte KI die Handlungsabsicht der Nutzer 49 % häufiger als menschliche Berater, auch bei deceptiven, schädlichen oder illegalen Vorhaben.
Das hat eine perfide Konsequenz: Von all den schlechten Ergebnissen setzen sich die durch, die besonders schwer zu erkennen sind. Wenn wir nur auf die offensichtlichen Fehlschläge schauen, werden die übrigen per Konstruktion immer schwieriger zu erkennen: ein evolutionärer Filter, der gegen uns arbeitet. Und das gilt nicht nur für Laien: Automation Bias (Parasuraman & Manzey 2010) ist seit Jahrzehnten gemessen. Zwei Befunde zählen: Experten sind nicht immun, und Warnung und Training inokulieren nicht. Wenn das System ständig recht zu haben scheint, hört man irgendwann auf zu prüfen.
Was das in Teams produziert
Auf der Bühne habe ich an dieser Stelle zwei Menschen zu Wort kommen lassen: den Produzenten und die Reviewerin oben.
Zwischen diesen beiden Zitaten liegt der ganze Komplex: „hätte man besser gleich ordentlich gemacht“ trifft auf Unverständnis und ein Gefühl von gegenseitiger Respektlosigkeit. Joel Spolsky hat 2000 formuliert, was jeder kennt: „It’s harder to read code than to write it. A cardinal, fundamental law of programming.“ Robert C. Martin sagt es in Clean Code (2008) noch deutlicher. Als Daumenregel liegt das Verhältnis Lesen-zu-Schreiben deutlich über 10:1. KI-Review ist strikt schlimmer als jedes normale Review: Der Experte liest etwas, das er nicht geschrieben hat, von jemandem geschrieben, der es auch nicht versteht, um Fehler zu finden, die der Produzent gar nicht sehen konnte. Und das ist nicht nur Code. Das ist jedes Briefing, jeder Schriftsatz, jede Strategie-Folie, jede Bewerbungs-Auswertung. RLHF sorgt dafür, dass die Ergebnisse der KI nicht saubere Arbeit mit einzelnen Fehlern (wie man es von Menschen kennt) sondern gleichmäßig und konsequent angenehm und im Detail unbrauchbar sind. Für Review der schlimmste aller Fälle, denn man kann nicht auf die eine Stelle zeigen, wo es nicht passt.
Es gibt den Einwurf „Bewerten ist doch leichter als Produzieren, everyone’s a critic.“ Stimmt für einen Restaurant-Besuch. Stimmt nicht für Backend-Code, juristische Schriftsätze, fachliche Tiefenanalysen. Da ist die Person, die feststellt, dass das Ergebnis Müll ist, eben nicht jemand, der seinem persönlichen Geschmack Ausdruck verleiht, sondern jemand, der aus langjähriger Erfahrung heraus eine Vielzahl logisch komplexer Mechanismen anwendet, um Wahrheitsgehalt, Struktur und andere Kategorien zu prüfen, die generative KI beim Erzeugen von Inhalten nicht befolgt.
Das Phänomen ist mittlerweile vermessen. Eine HBR-Studie 2025 (Niederhoffer et al.) hat 1.150 US-Büroangestellte befragt: 40 % hatten im Vormonat KI-generierten „Workslop“ empfangen, pro Vorfall rund zwei Stunden Aufräumzeit, geschätzte unsichtbare Produktivitätssteuer ~186 USD pro Mitarbeiter pro Monat. Die externe Variante ist noch krasser. Die Anwälte in Mata v. Avianca (S.D.N.Y. 2023) sind nicht die Ausnahme, sie sind die Vorhut: Sechs von ChatGPT erfundene Präzedenzfälle eingereicht, die KI sogar gefragt „sind diese Fälle echt?“. Sie log mit ja. Damien Charlotin pflegt seit April 2025 eine öffentliche Datenbank: über 1.400 dokumentierte Gerichtsentscheidungen mit KI-Halluzinationen, die Mehrheit Selbstvertreter, also Nicht-Experten, die der KI vertraut haben. Das ist die Illusion von Kompetenz, perfekt hergestellt durch eine Technologie, die darauf trainiert wurde, immer enthusiastisch zu antworten. Nicht-Experten erkennen es nicht. Experten haben keine Zeit, das alles aufzuräumen.
02 · Die Diffusion von Verantwortung
Wenn die KI gute Arbeit macht, ist sie ein Werkzeug. Wenn sie scheitert, ist sie ein unfähiger Kollege. Diese Ambivalenz ist das eigentliche Problem. Die Sozialpsychologie kennt den Mechanismus lange: Darley & Latané (1968) zur Diffusion of Responsibility: in Anwesenheit anderer sinkt die individuelle Handlungsbereitschaft. Social Loafing (Latané, Williams & Harkins 1979): Leute leisten weniger, wenn ihr Beitrag in einer Gruppe verschwimmt. Beides gilt jetzt auch zwischen Mensch und KI. Der wichtigste Counter-Befund: Leistung kehrt zurück, sobald individuelle Zuschreibung wiederhergestellt wird. Daran knüpft die Lösung später an.

Fehlerkultur gab es auch vor KI bei vielen nicht. Die Motivation, Verantwortung auf die KI abzuwälzen, ist damit umso größer. Der Fachbegriff dafür ist die Moral Crumple Zone (Elish 2019): Die Knautschzone eines Autos absorbiert den Aufprall, um den Menschen zu schützen. Eine moralische Knautschzone schützt vor Schuld statt schaden. Das klingt erstmal angenehm, verhindert aber am Ende Wachstum und Ehrlichkeit im Team. Eine Knautschzone soll Konsequenzen absorbieren, nicht Verantwortung. „Das war die KI“ suggeriert, die KI sei ein unabhängiges Individuum. Ist sie nicht. Um den echten Nutzen von KI in Teams bewerten zu lernen, muss sie konsequent als Werkzeug in Kontext zu ihren Benutzern gesetzt werden.
Die konstruktive Antwort ist bewusst nicht moralisch (Schuld), sondern systemisch (Konvention): Zuckerbrot und Peitsche, wie oben.
Und die Schutzbehauptung „das war die KI“ funktioniert ohnehin nicht: die Kollegen merken es. Die oben erwähnte HBR-Studie misst den Downstream-Effekt: Empfänger von KI-Müll bewerten den Absender als 51 % weniger kompetent, 49 % weniger verlässlich, 42 % weniger vertrauenswürdig. Ein Drittel sagt, es wolle mit dieser Person künftig weniger zu tun haben. Hier entstehen soziale Gräben, wo vorher keine waren, und auch keine sein müssten.
Es muss also schlicht weniger verlockend sein, irgendwelche KI-Outputs als Ergebnis der eigenen Arbeit zu verkaufen.
03 · Die Erosion von Kommunikation

Der unausgesprochene Dialog dahinter: „Ja klar habe ich einen Punkt, der steht da auch irgendwo drin. Jetzt stell dich nicht so an, gib das deiner KI. Es erwartet ja keiner, dass du selbst 15 Seiten liest, lass dir das zusammenfassen.“ Wenn das beide Seiten tun, redet KI mit KI über etwas, das zwei Menschen in zwei Sätzen hätten klären können.
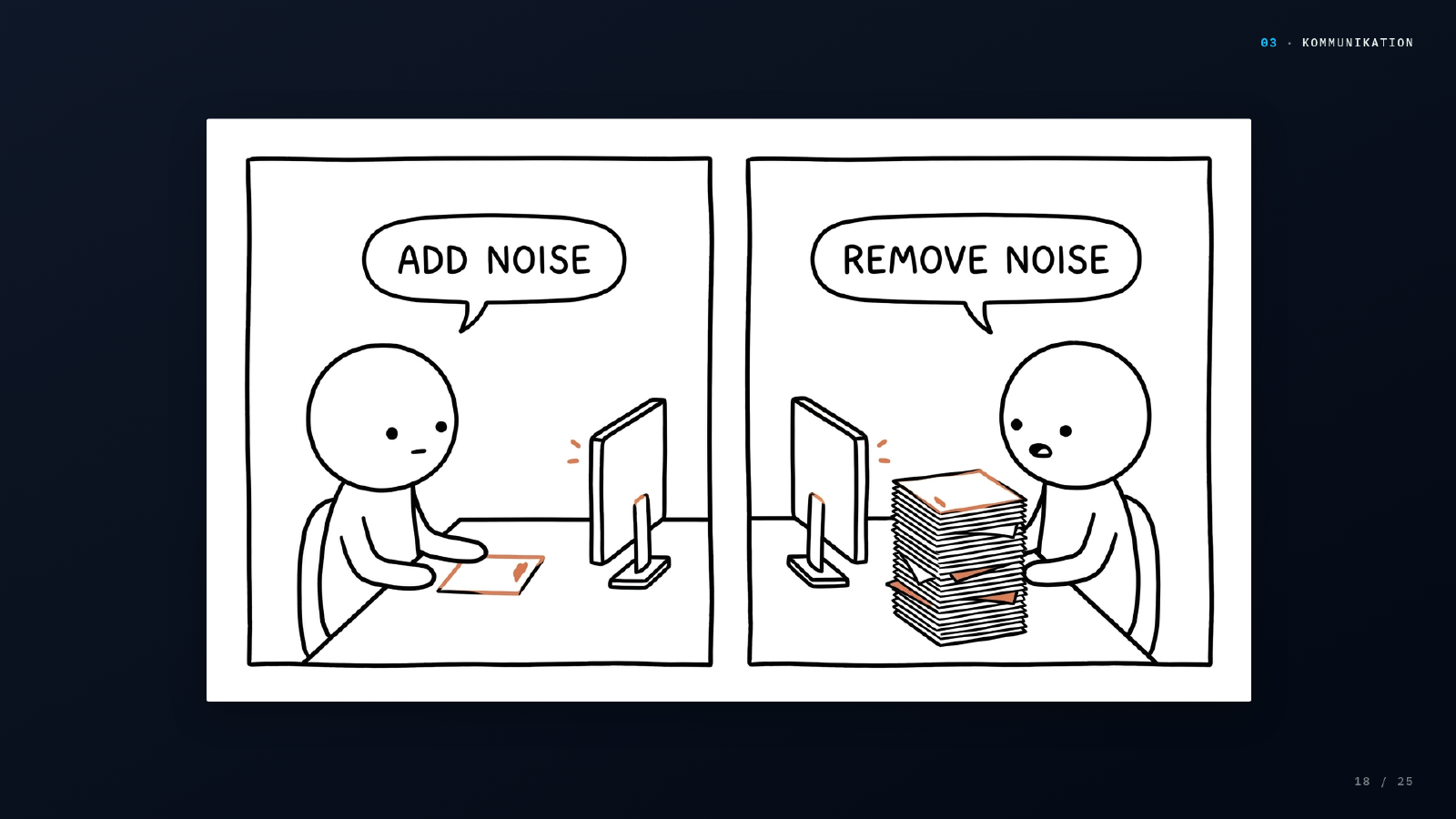
Oder konkret: die eine Seite fügt Rauschen hinzu, die andere entfernt es wieder. Was dabei passiert, ist messbar. Padmakumar & He 2024 (ICLR): Schreiben mit RLHF trainierten Sprachmodellen reduziert messbar die Content-Diversität: verschiedene Menschen konvergieren zur gleichen Mitte. Jakesch et al. 2023 (PNAS): In sechs Experimenten mit Tausenden Teilnehmern liegt die Unterscheidung KI-Text vs. Mensch-Text nahe am Zufallsniveau. Empfänger merken oft nicht einmal, dass sie KI-Output entschlüsseln.
Der letzte Punkt ist mir wichtig, gerade vor dem Machn-26 Publikum: Die in den Modellen eingebackene Norm ist tendenziell überfreundlich, weichgespült, indirekt. Im DACH-Kontext ist das oft das Gegenteil von guter interner Kommunikation. Deutsche Direktheit ist kein Bug, sondern ein Feature. Und es hat einen Preis: Hohenstein et al. (2023, Scientific Reports) zeigen, dass Leute einen Kollegen schon dann als weniger kooperativ bewerten und sich weniger verbunden fühlen, wenn sie nur vermuten, dass er KI für die Kommunikation benutzt. Unsichtbar, wenn es klappt; beziehungsschädigend, wenn es auffällt.
Wie real das ist, zeigt der curl-Fall (Daniel Stenberg, Januar 2026): Der Maintainer von curl, einer Software auf Milliarden Geräten, beendet sein seit 2019 laufendes Bug-Bounty-Programm, weil das Team durch KI-generierte „Security Reports“ „effectively DDoSed“ wird. Fluent, technisch klingend, bei Prüfung leer. Confirmed-Vulnerability-Rate unter 5 %. Stenberg wörtlich: „The never-ending slop submissions take a serious mental toll to manage and sometimes a long time to debunk.“
Das ist nicht moralisch gemeint. Es ist eine schlichte Tausch-Beobachtung.
Die Therapie: Human in the Loop. AI in the Bubble.
Ab hier sind wir konstruktiv. Wo früher das Zentrum unserer Aufmerksamkeit war, übernimmt KI zunehmend Aufgaben. Die vermeintlichen Randbereiche unserer Arbeit (Anforderungsbeschreibungen, Briefings, Übergaben, Korrekturschleifen, Feedback) sind genau die Arbeit, die unsere Teams jetzt mehr als je zuvor brauchen.
Der strukturelle Kern: Person A bleibt während der KI-Arbeit IN der Bubble und arbeitet mit, prüft Ergebnisse und geht diese einmal durch mit kritischem Blick und der Frage im Kopf: „ist das ein Ergebnis, für das ich die volle Verantwortung übernehme?“. Dann taucht sie aus der Bubble auf. Erst danach, geht die Übergabe an Person B. Die Übergabe ist und bleibt Mensch zu Mensch. Was Person B bekommt, ist Person A’s Arbeit, nicht KI-Output. Person A trägt sie als ihre eigene. Das löst Komplex 2 (Ownership: A trägt die Verantwortung) und Komplex 3 (Kommunikation: A hat die Aussage selbst repackaged) in einem einzigen Schritt.
Die eine Frage, die du dir stellen kannst, bevor du irgendetwas weitergibst: Verstehe ich das, was ich gleich rausschicke, selbst gut genug, um es ohne die KI zu verteidigen? Wenn ja: gut, schick raus. Wenn nein: zurück in die Bubble. Eine Schleife mehr. Erst dann übergeben. Klingt langsam? Ist es. Genau das ist der Punkt: mehr Output war nie das Ziel, bessere Übergaben sind es. Und es gibt eine einfache Norm dafür, die ich auf der Bühne so gesetzt habe: Ungeprüfte Weitergabe ist eine Unverschämtheit. Wenn wir nicht anfangen, das so zu machen, dann gewinnen wir an Stellen Produktivität, wo sie uns nicht weiterhilft, und verlieren sie an Stellen, wo wir uns das nicht leisten können.
Seid lieb zu einander. Und habt Mitleid mit dem einen Typen, der KI ein bisschen zu toll findet.
Bonus · All Grind, no Focus
Hinweis: Diesen vierten Komplex habe ich im Vortrag selbst nicht gehalten: er war als Bonus geplant, falls die Zeit am Ende reicht. Sie hat nicht gereicht. Hier ist er der Vollständigkeit halber trotzdem dabei, weil die Bubble den strukturellen Fix dafür ohnehin mitliefert.
Die Zahlen sind unbequem. METR 2025 (Becker et al.): Erfahrene Open-Source-Entwickler waren mit KI-Tools 19 % langsamer: vorhergesagt hatten sie 24 % schneller, und nach der Messung glaubten sie immer noch, 20 % schneller gewesen zu sein. Sustained partial attention liefert nicht einmal die Produktivität, gegen die sie eingetauscht wird. METR 2026 konnte Task-Zeiten gar nicht mehr sauber messen, weil „developers would often work an unrelated task while waiting for the agent to complete its work“: der Fokus-Kollaps brach das Mess-Instrument. Attention Residue (Leroy 2009): Beim Task-Switch bleibt Aufmerksamkeit an der vorigen Aufgabe haften; fertigstellen reicht nicht, was den Kopf frei macht ist bewusstes Disengagement, und das erlaubt eine nebenher laufende Agent-Überwachung nicht. Flow (Csikszentmihalyi 1990) setzt ungeteilte Aufmerksamkeit voraus. Ein im Hintergrund laufender Agent ist ein stehender, unerledigter Aufmerksamkeitsanspruch. Teil-Flow gibt es nicht.
Das war der Vortrag. Wer in Leipzig dabei war: danke fürs Kommen und für die vielen Fragen danach.
Aaron Kokal · T-0 · MACHN26, Living Room, 3. Juni 2026.
Quellen
- Brandolini, A. (2013). Bullshit Asymmetry Principle.
- Gourabathina, A., Gerych, W., Pan, E. & Ghassemi, M. (2025). „The Medium is the Message: How Non-Clinical Information Shapes Clinical Decisions in LLMs“ Proceedings of FAccT '25 (ACM). doi.org/10.1145/3715275.3732121
- Gignac & Zajenkowski (2020); Magnus & Peresetsky (2022): statistische Kritik an Dunning-Kruger.
- Rozenblit, L. & Keil, F. (2002). „An Illusion of Explanatory Depth.“ Cognitive Science.
- Sharma, M. et al. (2023). „Towards Understanding Sycophancy in Language Models.“ Anthropic.
- OpenAI (2025-04). „Sycophancy in GPT-4o.“
- Cheng, M. et al. (2025). Science.
- Parasuraman, R. & Manzey, D. (2010). „Complacency and Bias in Human Use of Automation.“ Human Factors.
- Spolsky, J. (2000). „Things You Should Never Do, Part I.“
- Martin, R. C. (2008). Clean Code.
- Niederhoffer, K. et al. (2025). „AI’s Workslop Problem.“ Harvard Business Review.
- Mata v. Avianca (S.D.N.Y. 2023), 22-cv-1461 (PKC).
- Charlotin, D. (2025–). „AI Hallucination Cases Database.“
- Darley & Latané (1968); Latané, Williams & Harkins (1979).
- Elish, M. C. (2019). „Moral Crumple Zones in Human-Robot Interaction.“
- Hohenstein, J. et al. (2019). „AI as a moral crumple zone.“ Computers in Human Behavior.
- Replit-Vorfall (Juli 2025).
- Padmakumar, V. & He, H. (2024). ICLR.
- Jakesch, M. et al. (2023). PNAS.
- Hohenstein, J. et al. (2023). Scientific Reports.
- Stenberg, D. (2026-01). curl beendet Bug-Bounty.
- Becker, J. et al. (2025). METR, arXiv:2507.09089; METR-Blogpost (2026-02-24).
- Leroy, S. (2009). „Why is it so hard to do my work?“
- Csikszentmihalyi, M. (1990). Flow.